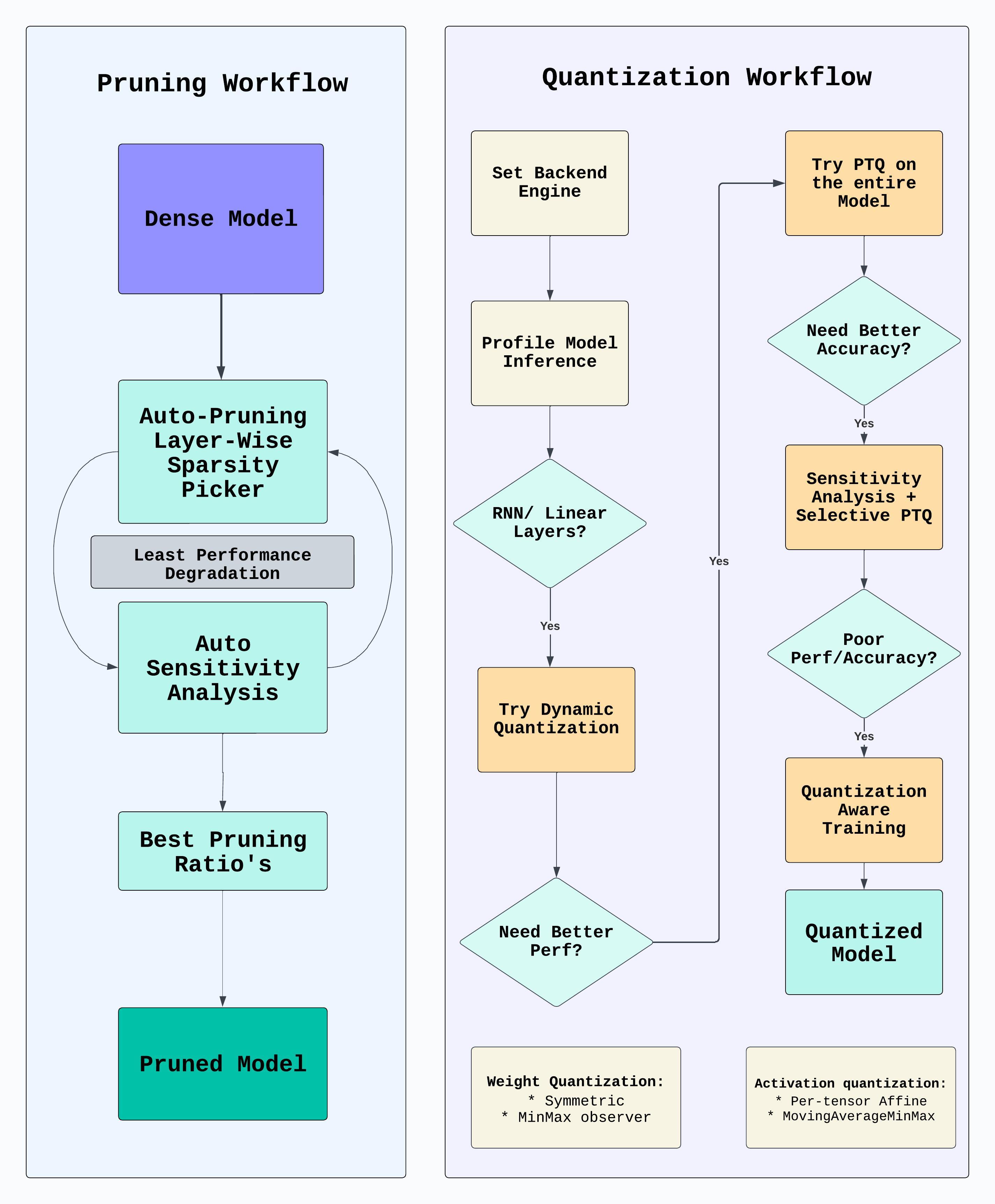
Workflow
Pruning Workflow:
Overview: - Pruning is a technique used to reduce the size of a neural network by eliminating unnecessary connections (weights). - The goal is to create a more efficient and lightweight model without sacrificing performance.
Identifying Insignificant Weights: - Train the neural network as usual. - Analyze the trained model to identify weights that contribute less to the overall performance. - Weights with low magnitudes are considered less important.
Pruning Criteria: - Define a pruning threshold or criteria for determining which weights to prune. - Common criteria include magnitude-based pruning, where weights below a certain threshold are pruned.
Pruning Process: - Apply the pruning criteria to the identified weights. - Set the weights below the threshold to zero or remove them from the network. - This results in a sparse or pruned model.
Fine-tuning: - Retrain the pruned model to recover any lost accuracy. - Fine-tuning helps the model adapt to the changes introduced by pruning.
Benefits: - Reduced model size, leading to faster inference and lower memory requirements. - Potential speedup during training due to the sparsity introduced by pruning.
Quantization Workflow:
Overview: - Quantization involves reducing the precision of the weights and activations in a neural network. - It replaces floating-point numbers with lower bit-width representations, such as integers.
Quantization Levels: - Choose the bit-width for quantization (e.g., 8-bit, 16-bit). - Lower bit-widths lead to reduced memory and computational requirements but may impact model accuracy.
Quantization of Weights and Activations: - Apply quantization to both the model weights and activations. - Convert floating-point values to their quantized equivalents using a specified quantization scheme.
Quantization Schemes: - Common quantization schemes include linear quantization, where values are uniformly quantized within a specified range, and non-linear quantization, which uses a non-uniform distribution.
Fine-tuning: - Retrain the quantized model to recover any accuracy loss. - Fine-tuning is crucial to adjust the model for the reduced precision.
Benefits: - Reduced memory footprint and storage requirements. - Accelerated inference due to the use of lower precision computations. - Improved deployment on devices with limited computational resources.