Efficient-Hyperparameter Auto Sensitivity Seach
Pruning in the context of deep learning involves removing certain weights or neurons from a neural network to make it more efficient and reduce its computational complexity. Sparsity levels refer to the proportion of weights or neurons that are pruned from the model. Determining the optimal sparsity level for pruning can be a challenging task and depends on various factors. Here are some considerations:
Task-specific Factors: - The nature of the task the model is performing can influence the optimal sparsity level. Some tasks may tolerate higher levels of pruning without significant loss of performance, while others may require a more conservative approach.
Model Architecture: - Different neural network architectures may respond differently to pruning. For example, smaller models may be more sensitive to pruning, while larger models may have more redundancy that can be pruned without affecting performance.
Dataset Characteristics: - The characteristics of the dataset used for training and testing can impact the optimal sparsity level. Complex datasets with diverse patterns may require a more intricate model, potentially reducing the amount of pruning that can be applied.
Training Duration: - The duration and complexity of the training process also play a role. Aggressive pruning may lead to faster training times, but it could result in a loss of model accuracy. Finding the right balance is essential.
Performance Metrics: - The choice of performance metrics is crucial. Some models may show good results on one metric but may perform poorly on others. It’s important to consider a range of evaluation metrics to get a comprehensive understanding of the model’s performance.
Iterative Pruning: - It’s often beneficial to perform iterative pruning, gradually increasing the sparsity level and evaluating performance at each step. This helps identify the point at which further pruning leads to a significant drop in performance.
Fine-Tuning: - After pruning, fine-tuning the model on the training data can help recover some of the lost performance. This process involves retraining the pruned model on the original task.
Resource Constraints: - The available computational resources can also influence the choice of sparsity level. More aggressive pruning may lead to models that can run on resource-constrained devices, but it may come at the cost of reduced accuracy.
Ultimately, finding the optimal sparsity level often involves experimentation and thorough evaluation. Researchers and practitioners typically perform multiple experiments to identify the best trade-off between model size, computational efficiency, and task performance.
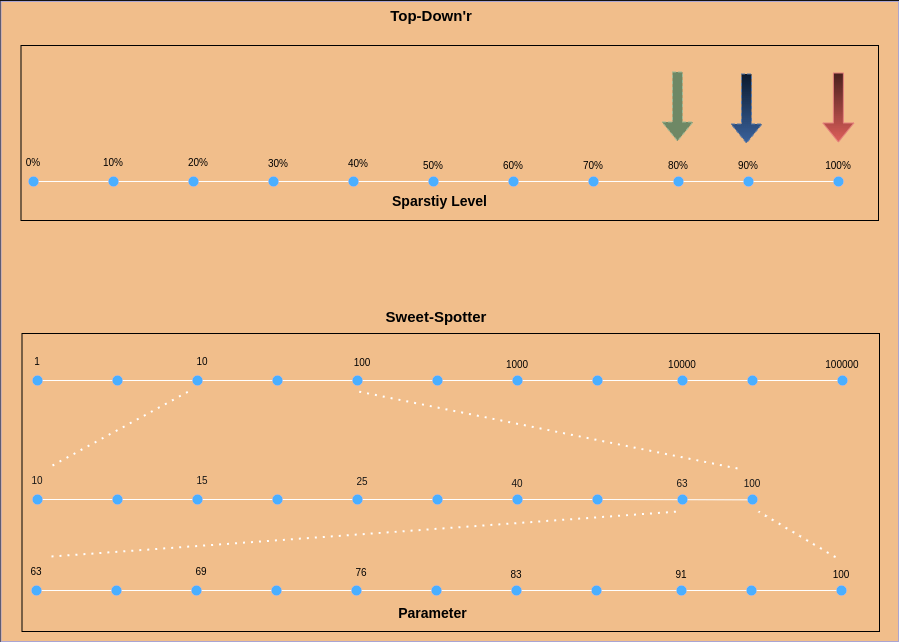
Hence we use the Efficient-Hyperparameter Search for Pruning to find the optimal sparsity level for Pruning or other techniques that require sensitivity as a hyperparameter. Two different methods are used to find the optimal sensitivity level as shown in the figure above. This ensemble of methods is used to find the optimal sensitivity level for the given model and dataset. Depending on technique and process used the optimal sensitivity level may vary. Hence we use an ensemble of methods to find the optimal sensitivity level for the given model and dataset.
This block can be found the sconce package as sconce.pruning.auto_sensitivity_picker.